

Durante años, cuando se hablaba de aplicaciones con inteligencia artificial, la conversación se centraba casi siempre en Python y sus librerías. No era raro escuchar que, si querías hacer algo serio con machine learning o con modelos de lenguaje, tenías que recurrir a ese ecosistema.
Como desarrollador que lleva toda su carrera confiando en Java y especialmente en Spring Boot, esa visión me resultaba limitada. ¿De verdad no había espacio para aplicar todo lo que ya teníamos aprendido en ingeniería de software —modularidad, patrones de diseño, escalabilidad— al mundo de la IA?
La respuesta llegó con Spring AI, un proyecto que por fin pone a Java y a Spring en el mapa de la inteligencia artificial generativa.
De Spring Boot a Spring AI: continuidad natural
Spring Boot se ha ganado la fama de ser uno de los frameworks más potentes y prácticos para construir aplicaciones empresariales. Su filosofía es clara: simplificar lo complejo, pero sin perder robustez ni escalabilidad. Y Spring AI no es otra cosa que la extensión de esos mismos principios al mundo de la IA.
En lugar de obligarnos a depender de SDKs propietarios, o a escribir código específico para cada proveedor de modelos, Spring AI ofrece un lenguaje común. Lo que antes requería condicionar nuestro diseño a si usábamos OpenAI, Anthropic o Google, ahora se resuelve con una API única y portable.
Esto significa que puedes desarrollar tu aplicación de negocio sobre una base sólida y, si mañana decides cambiar de proveedor de IA, no necesitas rehacer medio proyecto. Desde la perspectiva de ingeniería de sistemas, esta desacoplación es oro puro.
IA como un componente más de la arquitectura
Una de las cosas que más me gusta de Spring AI es que deja de tratar a la inteligencia artificial como un experimento aislado y la incorpora a la arquitectura de software de siempre.
Tus aplicaciones ya gestionan bases de datos, APIs externas, colas de mensajería, microservicios… Ahora puedes sumar a esa lista un cliente de IA que se comporta como cualquier otro componente Spring: configurable, observable y escalable.
La idea es sencilla pero poderosa: tu aplicación aporta los datos y APIs; el modelo generativo procesa esa información y devuelve valor. Todo ello gobernado con las mismas herramientas de siempre, como Micrometer para métricas o Resilience4j para resiliencia.
Ejemplos que cambian la práctica
Hablemos de un caso real. Supongamos que quieres extraer información estructurada de un texto, algo muy común en cualquier negocio: datos de clientes, información de facturas o resúmenes de contratos.
Con Spring AI, la respuesta del modelo se puede mapear directamente a un POJO tipado. No hay que andar parseando JSON a mano ni peleándose con cadenas mal formateadas.
public record CustomerInfo(String name, String email, int age) {}
CustomerInfo info = chatClient.prompt()
.user("Extract name, email and age from this text: ...")
.call()
.entity(CustomerInfo.class);
Lo que obtenemos es un objeto Java listo para usar en nuestra lógica de negocio, con la seguridad del tipado fuerte y la posibilidad de validar en tests unitarios.
Otro ejemplo clave: RAG (Retrieval Augmented Generation). En entornos empresariales, los modelos no valen de mucho si no pueden acceder a los datos propios de la organización. Spring AI ofrece conectores listos para usar con bases vectoriales como Postgres/PGVector, Pinecone o Redis. Eso significa que puedes indexar documentos, buscar por similitud y ofrecer a la IA contexto real sin reinventar la rueda.
Escalar en serio: la perspectiva de ingeniería
Lo bonito de jugar con un chatbot casero es que funciona en tu portátil. Lo difícil es llevar esa idea a producción en una empresa donde los sistemas deben ser confiables, auditables y escalables. Aquí es donde Spring AI brilla.
- •
Escalabilidad horizontal: los clientes de Spring AI son stateless, lo que facilita desplegar múltiples instancias detrás de un balanceador. La memoria conversacional se puede externalizar en Redis o Postgres, garantizando coherencia en clusters grandes y evitando un sPOF (single point of failure) en la instancia que atiende al usuario.
- •
Resiliencia multi-proveedor: puedes configurar circuit breakers para redirigir llamadas de un proveedor a otro en caso de fallo. Desde la ingeniería de sistemas, esto es clave: evitas puntos únicos de fallo y reduces la dependencia de un solo proveedor.
- •
Observabilidad unificada: cada interacción con el modelo expone métricas de latencia, uso de tokens y throughput. Esto significa que puedes monitorizar la IA igual que monitorizas tu base de datos o tu API REST, integrando todo en Grafana o Prometheus.
- •
Coste y eficiencia: invocar un LLM no es barato. Por eso Spring AI soporta streaming (recibir tokens parciales en tiempo real) y cachés para evitar llamadas redundantes. Esto permite reducir costes y mejorar el time-to-first-byte, algo crítico en experiencia de usuario.
Más allá del prompt: Tools + MCP (agentes que actúan)
Uno de los avances más interesantes es la capacidad de exponer herramientas (Tools) que los modelos pueden invocar. Esto convierte a tu aplicación en un ecosistema donde la IA no se limita a responder, sino que actúa sobre tu dominio (consulta pedidos, crea incidencias, calcula tarifas, etc.).
Además, Spring AI se integra con el estándar MCP (Model Context Protocol) para que esas mismas capacidades se expongan de forma descubrible y segura a clientes como Claude Desktop o Cursor. En la práctica: tu app Spring Boot se convierte en un Servidor MCP; los clientes MCP detectan tus herramientas y las usan con el consentimiento y permisos adecuados.
Por ejemplo, puedes definir un servicio en tu aplicación:
@Service
public class WeatherService {
@Tool(name = "getWeather", description = "Get weather by city")
public Weather getWeather(String city) {
// llamada a API externa
}
}
Si quieres montar el servidor MCP paso a paso, aquí tienes una guía clara:
ETL y RAG: arquitecturas con futuro
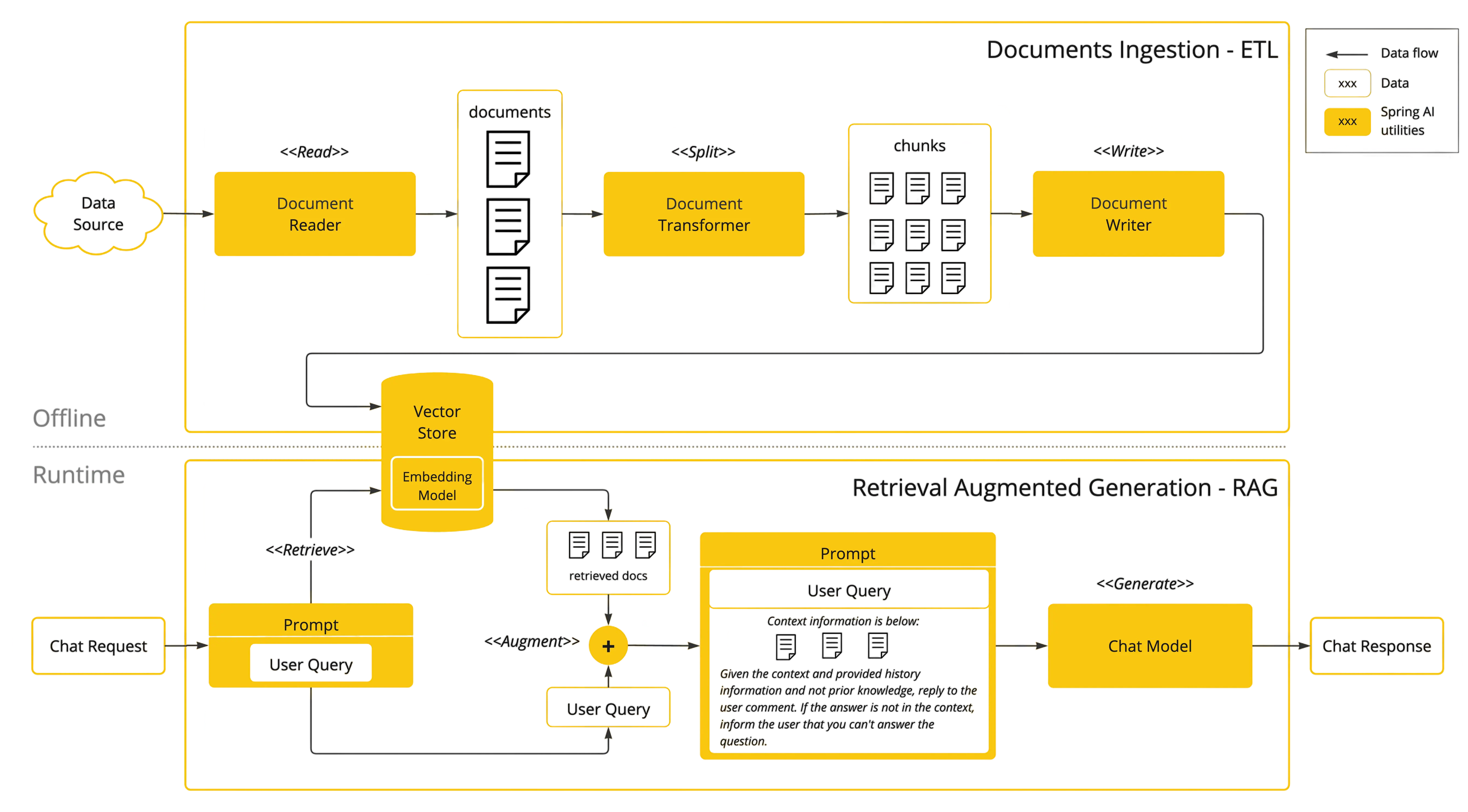
Conectar la IA a tus datos no va de “subir PDFs” y cruzar los dedos. Si quieres respuestas útiles, repetibles y auditables, necesitas dos piezas que trabajen juntas: un pipeline ETL que prepara y gobierna tu corpus, y un RAG que lo explota de forma precisa y eficiente en cada consulta.
ETL (Extract–Transform–Load)
Piensa en el ETL de Spring AI como una tubería explícita y testeable: lees documentos, los transformas en fragmentos coherentes, los enriqueces con metadatos y los cargas en tu vector store. No hay magia: son interfaces claras (DocumentReader, DocumentTransformer, DocumentWriter) que puedes orquestar como cualquier otro componente Spring.
1) Extracción.
Arranca donde esté tu conocimiento: BBDD, APIs, wikis o ficheros. Puedes hacerlo por lotes (cron/batch) o en tiempo real (webhooks/colas). Spring AI ya trae readers listos —por ejemplo, JsonReader, TextReader, PagePdfDocumentReader— para convertir fuentes en List<Document>.
2) Transformación.
Limpia el texto (OCR si hace falta), elimina ruido y segmenta en chunks semánticos. Evita "cortes a ciegas": si respetas párrafos/encabezados, el modelo entiende mejor. El TokenTextSplitter divide por tokens (tamaño objetivo, mínimo de caracteres, número máximo de chunks, etc.) y es el caballo de batalla en esta fase.
3) Enriquecimiento. Añade metadatos útiles (fuente, fecha de vigencia, idioma, tenant, confidencialidad, versión). Sin metadatos no hay filtros finos, ni auditoría, ni multitenancy serio.
4) Carga. Genera embeddings y sube los fragmentos al vector store (PGVector, Pinecone, Redis, etc.). Para evitar cortes, reindexa en un índice canario y conmuta con aliases cuando verifiques calidad/consistencia. El pipeline mínimo en “estilo función” es literalmente una línea:
// Cargar a Vector DB: PDF -> split por tokens -> write
vectorStore.write(tokenTextSplitter.split(pdfReader.read()));
Operativa que marca la diferencia.
- •Actualizaciones incrementales (no rehagas todo si cambió una página).
- •Lineage (qué fragmento salió de qué documento/versión) para explicar respuestas y auditar.
- •Control de acceso por metadatos/RLS a nivel de chunk en multitenancy.
- •Observabilidad del pipeline: tasa de ingesta, tamaño de chunk, tiempo de indexación, errores y coste por millón de tokens embebidos.
RAG (Retrieval Augmented Generation)
RAG es lo que convierte el corpus en contexto dinámico: ante cada pregunta, recuperas lo relevante y construyes el prompt con ese material, en vez de confiar en "lo que el modelo recuerde". Spring AI te deja hacerlo modular (bloques RAG) o tirar de Advisors listos para producción.
1) Recuperación.
Consulta por similitud en el vector store. El advisor más directo es QuestionAnswerAdvisor:
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(userText)
.call()
.chatResponse();
2) Filtros por metadatos. Limita por tenant, idioma, categoría o confidencialidad para seguridad y menor ruido. Puedes fijar filtros por defecto o pasarlos en tiempo de ejecución:
String content = chatClient.prompt()
.user("Please answer my question XYZ")
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'"))
.call()
.content();
3) Gestión de contexto. El contexto tiene un presupuesto de tokens. Deduplica, comprime y prioriza por score antes de construir el prompt. Pide citas para trazar la respuesta hasta el origen.
4) Construcción del prompt.
Separa instrucciones, pregunta y contexto y define reglas de conflicto (más reciente vs. mayor autoridad). Con RetrievalAugmentationAdvisor pasas a un RAG modular (pre-retrieval, retrieval, post-retrieval, generación), y puedes añadir compresión/reescritura de consulta, re-rankers o “no contestar si no hay contexto”:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
5) Optimización y métricas. Cachea consultas y plantillas de contexto; monitoriza hit-rate, recall@k, NDCG (si tienes ground truth), TTFB con/sin streaming, tokens por respuesta y % de respuestas con cita válida. Lanza alertas si la recuperación devuelve 0 resultados o cae el score bajo umbral. Así conviertes el RAG en un componente con SLA, no en una caja negra.
Conclusión
Lo que más me entusiasma de Spring AI no es solo lo que ofrece hoy, sino lo que representa: la consolidación de la IA como un componente de ingeniería de software empresarial.
Ya no hablamos de pruebas aisladas en Python, sino de sistemas escalables, observables, gobernables y portables, construidos con las mismas prácticas que usamos para microservicios, APIs y bases de datos.
Java + Spring Boot ya era una de las mejores bases para aplicaciones empresariales. Con Spring AI, damos un paso más: la inteligencia artificial entra en nuestro stack no como un añadido, sino como una pieza central, lista para escalar y aportar valor real.
Y sí, quizá sea un friki de Java, pero me encanta comprobar que un lenguaje no muere aunque pasen los años, que se reinventa y que mantiene una comunidad inmensa empujando el ecosistema hacia delante.
— Carlos Martínez García-Villarrubia