
Una mirada en profundidad a cómo diseñar sistemas distribuidos resilientes con Kafka, desde la ingeniería y no solo desde la programación.
Introducción: La Evolución Hacia Arquitecturas Basadas en Eventos
Durante años, la mayoría de las aplicaciones web se han basado en el patrón request-response: un cliente realiza una petición HTTP, el servidor la procesa y devuelve una respuesta. Este modelo es intuitivo y fácil de implementar, pero cuando el negocio crece y los sistemas se vuelven más complejos, aparecen problemas significativos.
Imagina una tienda online típica: cuando un cliente confirma su pedido, múltiples cosas deben suceder casi simultáneamente. El sistema de facturación necesita generar la factura, el inventario debe actualizar el stock disponible, el servicio de notificaciones tiene que enviar un email de confirmación, y el sistema de logística debe preparar el envío. En una arquitectura tradicional, el servicio de pedidos tendría que llamar directamente a cada uno de estos servicios, creando una cadena de dependencias que se vuelve frágil y difícil de mantener.
Una Solución Natural: El Paradigma Event-Driven
La arquitectura dirigida por eventos (Event-Driven Architecture, EDA) se plantea como una alternativa elegante a este problema. En lugar de que los servicios se invoquen directamente entre sí, cada servicio publica eventos cuando algo importante ocurre, y otros servicios interesados reaccionan de forma asíncrona, sin que el productor del evento necesite conocer quién lo va a consumir.
Loading diagram...
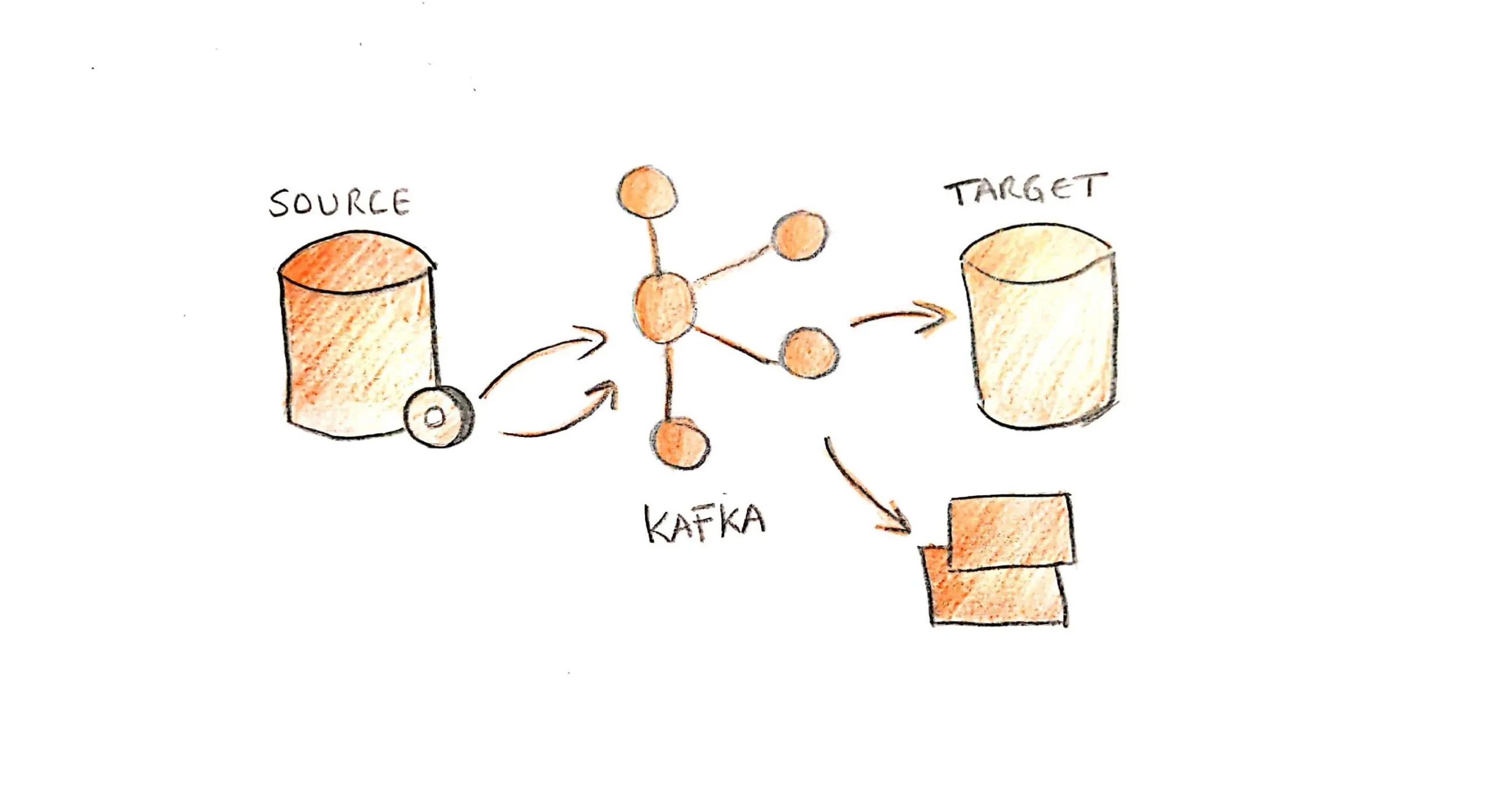
El diagrama anterior muestra cómo un único evento generado por el servicio de pedidos se distribuye automáticamente a todos los servicios interesados. Cada servicio procesa el evento de forma independiente y a su propio ritmo. Si el servicio de notificaciones está temporalmente caído, los demás servicios continúan funcionando normalmente. Cuando el servicio se recupere, procesará los eventos pendientes sin afectar al resto del sistema.
Las Ventajas del Desacoplamiento
La clave está en el desacoplamiento temporal y espacial: los servicios no se conocen entre sí, pueden procesar a diferentes velocidades, y si uno falla, los otros continúan funcionando. Es como pasar de un sistema de llamadas telefónicas directas a un sistema de radio donde cada estación puede escuchar las frecuencias que le interesan.
Apache Kafka: Fundamentos y Diferenciadores Clave
Apache Kafka nació en LinkedIn para resolver un problema muy específico: capturar y procesar la actividad de millones de usuarios en tiempo real. Lo que comenzó como una solución interna se ha convertido en la columna vertebral de sistemas que manejan trillones de mensajes diarios en empresas como Netflix, Uber, y Airbnb.
Pero Kafka no es simplemente una "cola de mensajes más rápida". Sus características lo diferencian fundamentalmente de sistemas tradicionales como RabbitMQ o ActiveMQ:
¿Qué Hace a Kafka Diferente?
Persistencia que Cambia las Reglas del Juego
A diferencia de las colas tradicionales donde los mensajes se eliminan una vez consumidos, Kafka almacena todos los eventos en un log distribuido y replicado. Esto significa que puedes "rebobinar el tiempo" y procesar eventos que ocurrieron hace horas, días, o incluso semanas. Es como tener una grabación completa de todo lo que ha pasado en tu sistema.
Escalabilidad Sin Límites
Kafka está diseñado desde cero para escalar horizontalmente. Cuando necesitas más capacidad, simplemente añades más brokers al cluster. No hay un cuello de botella central que limite el crecimiento. Empresas como LinkedIn procesan más de 4.5 trillones de mensajes por día con este enfoque.
Paralelización Inteligente
Los topics en Kafka se dividen automáticamente en particiones, y cada partición puede ser procesada independientemente por diferentes consumidores. Esto permite que el sistema escale no solo en términos de almacenamiento, sino también de procesamiento paralelo.
Loading diagram...
En este diagrama vemos cómo Kafka distribuye automáticamente los mensajes. Los productores A y B envían pedidos al topic "Pedidos", que está dividido en 3 particiones. Kafka distribuye los mensajes usando una función hash sobre la clave del mensaje (por ejemplo, el ID del cliente), garantizando que todos los pedidos de un cliente específico vayan siempre a la misma partición y se procesen en orden. Cada partición es procesada por un consumidor diferente, permitiendo paralelización sin perder el orden de eventos por cliente.
Flexibilidad en el Consumo
Una de las características más poderosas de Kafka es que diferentes servicios pueden suscribirse al mismo topic con diferentes propósitos y velocidades. El servicio de analytics puede procesar todos los eventos para generar reportes diarios, mientras que el servicio de notificaciones procesa solo eventos específicos en tiempo real. Cada consumidor mantiene su propio "puntero" en el log de eventos, permitiendo esta flexibilidad.
Patrones Arquitectónicos Avanzados
Event Sourcing: La Historia Completa como Fuente de Verdad
En las aplicaciones tradicionales, almacenamos únicamente el estado actual de las entidades. Si queremos saber el saldo de una cuenta bancaria, consultamos una tabla que contiene "Saldo actual: 500€". Esta aproximación funciona bien para consultas simples, pero perdemos información valiosa sobre cómo llegamos a ese estado.
Event Sourcing propone un enfoque radicalmente diferente: en lugar de almacenar solo el estado final, registramos todos los eventos que han ocurrido, manteniendo un historial completo e inmutable de la vida de cada entidad.
Loading diagram...
El diagrama muestra la diferencia fundamental entre ambos enfoques. En el modelo tradicional (parte superior), solo conocemos el estado final. En Event Sourcing (parte inferior), cada cambio genera un evento inmutable que se almacena permanentemente. El saldo actual se obtiene "reproduciendo" todos los eventos en orden cronológico. Si en algún momento necesitamos saber el saldo que tenía la cuenta el 2 de enero, simplemente reproducimos eventos hasta esa fecha.
¿Por Qué Event Sourcing es Tan Poderoso?
Event Sourcing transforma radicalmente cómo pensamos sobre los datos, ofreciendo ventajas que van mucho más allá del simple almacenamiento:
Auditabilidad Completa: Cada cambio queda registrado automáticamente con su contexto completo. No solo sabes qué cambió, sino quién lo hizo, cuándo, por qué, y desde qué sistema. En sectores regulados como finanzas o salud, esto elimina la necesidad de implementar logs de auditoría complejos porque el sistema de eventos ES tu log de auditoría.
Debugging Temporal: Event Sourcing te da una máquina del tiempo para debugging. Cuando encuentras un bug en producción, puedes recrear exactamente el estado del sistema en cualquier momento del pasado. Es como tener una grabación completa de todo lo que pasó, no solo una foto del resultado final. Puedes reproducir eventos hasta justo antes del problema, añadir logs adicionales, y observar exactamente qué causó el fallo.
Flexibilidad para Nuevos Casos de Uso: Cuando el negocio evoluciona, puedes generar nuevas vistas sin migrar datos. Si el equipo de marketing necesita un dashboard para analizar patrones de compra por región, simplemente procesas todos los eventos históricos para construir esa nueva vista. Los eventos contienen toda la información contextual necesaria para generar cualquier proyección futura.
Cómo Funciona en la Práctica
Considera un sistema de e-commerce real: en lugar de actualizar registros existentes, cada acción del usuario genera un evento inmutable. Cuando un cliente crea un pedido, generas un evento PedidoCreado que captura todos los detalles iniciales: productos, precios, descuentos aplicables, información del cliente. Si añade productos, cada cambio produce un ProductoAñadido con timestamp exacto. Los descuentos se documentan con eventos DescuentoAplicado que registran qué promociones se aplicaron y bajo qué condiciones.
El flujo continúa: PedidoConfirmado marca el momento exacto de confirmación con datos de pago, PagoProcessado registra los detalles del procesamiento incluyendo el método usado y el resultado, y finalmente PedidoEnviado actualiza el estado con información de tracking. El estado actual del pedido se obtiene reproduciendo todos estos eventos en orden cronológico, pero aquí viene lo interesante: puedes generar vistas completamente diferentes de los mismos datos. Una vista optimizada para mostrar al cliente, otra para el departamento de contabilidad, y otra para logística, todas derivadas de la misma fuente de verdad inmutable.
CQRS: Separando Escrituras y Lecturas para Máximo Rendimiento
Command Query Responsibility Segregation (CQRS) reconoce una verdad fundamental sobre la mayoría de aplicaciones empresariales: las necesidades de escritura y lectura son completamente diferentes, y optimizar para ambas en el mismo modelo limita el rendimiento de ambas.
Los comandos (escrituras) deben ser estrictos con las validaciones, mantener consistencia transaccional, y aplicar reglas de negocio complejas. Las consultas (lecturas), por el contrario, necesitan ser extremadamente rápidas, pueden tolerar datos ligeramente desactualizados, y suelen requerir agregaciones y vistas especializadas.
Loading diagram...
El diagrama ilustra cómo CQRS separa completamente las responsabilidades. En el lado izquierdo, los comandos pasan por validaciones estrictas y generan eventos que se almacenan en el event store. Estos eventos fluyen a través de Kafka hacia múltiples proyecciones especializadas. En el lado derecho, las consultas acceden a estas proyecciones optimizadas sin afectar el lado de comandos.
Optimización Especializada: Dos Mundos, Dos Estrategias
La belleza de CQRS radica en cómo cada lado puede optimizarse para su propósito específico:
Lado de Comandos (Escrituras):
- •Se enfoca en la correctitud y validación
- •Utiliza bases de datos transaccionales como PostgreSQL o SQL Server
- •Implementa validaciones estrictas de reglas de negocio
- •Maneja concurrencia y bloqueos cuando es necesario
- •La velocidad de respuesta es secundaria a la integridad de datos
Lado de Consultas (Lecturas):
- •Está optimizado para velocidad y disponibilidad
- •Mantiene múltiples almacenes especializados para casos de uso específicos
- •Redis para consultas con latencias de milisegundos
- •Elasticsearch para búsquedas textuales complejas
- •ClickHouse para analytics y agregaciones de grandes volúmenes
- •APIs GraphQL para consultas flexibles en frontend
Viendo CQRS en Acción: Un E-commerce Real
Cuando un cliente ejecuta el comando "CrearPedido", el sistema del lado de escritura trabaja meticulosamente:
- •Valida disponibilidad de stock consultando inventario en tiempo real
- •Aplica descuentos y promociones según reglas de negocio complejas
- •Calcula impuestos basándose en la ubicación del cliente y regulaciones locales
- •Verifica límites de crédito y métodos de pago disponibles
Solo después de todas estas validaciones genera el evento "PedidoCreado" con la información validada y lo almacena en el event store transaccional.
Este único evento alimenta automáticamente múltiples proyecciones especializadas:
- •Vista Cliente: "Mis pedidos" optimizada para consultas rápidas del historial personal
- •Vista Analytics: Agregaciones pre-calculadas por producto, región y período
- •Vista Logística: Pedidos pendientes optimizada para operaciones de almacén
- •Vista Inventario: Proyecciones de demanda futura para optimizar reabastecimiento
Los Beneficios Arquitectónicos que Transforman tu Sistema
Esta separación genera beneficios arquitectónicos profundos. Durante eventos como Black Friday, puedes escalar lecturas y escrituras independientemente: las consultas se disparan 10x (usuarios navegando productos) mientras las escrituras solo aumentan 3x (compras reales). Cada proyección usa exactamente la tecnología que necesita sin compromisos.
Lo más valioso es la evolución independiente que permite: cambiar cómo muestras datos no afecta la lógica de negocio de escritura, y viceversa. Puedes agregar nuevas proyecciones para necesidades emergentes sin tocar el código crítico de comandos.
Outbox Pattern: Garantizando Consistencia Entre Datos y Eventos
Uno de los desafíos más sutiles pero críticos en arquitecturas event-driven es el problema del dual-write: necesitas guardar datos en tu base de datos local Y publicar un evento en Kafka para notificar a otros servicios. Si estas dos operaciones no son atómicas, pueden fallar independientemente, causando inconsistencias peligrosas que son difíciles de detectar y corregir.
Loading diagram...
El diagrama superior muestra el problema clásico: si la escritura a la base de datos tiene éxito pero la publicación a Kafka falla, el sistema queda en un estado inconsistente. El diagrama inferior muestra cómo el Outbox Pattern resuelve esto usando una sola transacción de base de datos que incluye tanto los datos principales como el evento a publicar.
El Peligroso Problema del Dual-Write
El problema surge en un escenario aparentemente simple: un cliente realiza un pedido y tu servicio debe guardar los datos en la base de datos local Y publicar un evento en Kafka para notificar a otros servicios. Parece directo, pero esconde una trampa peligrosa.
Imagina que guardas exitosamente el pedido en la tabla orders, pero justo cuando intentas publicar el evento "PedidoCreado" a Kafka, ocurre un problema de red temporal. El pedido está guardado en tu sistema, pero el servicio de facturación nunca se entera para generar la factura, el inventario no actualiza su stock para reflejar la reserva, y el cliente nunca recibe el email de confirmación.
La Solución Elegante: Una Sola Transacción Atómica
El Outbox Pattern resuelve esto de manera elegante transformando dos operaciones en una sola. En lugar de guardar el pedido y después intentar publicar a Kafka, guardas tanto el pedido como el evento a publicar en la misma transacción de base de datos. El pedido va a la tabla orders como siempre, pero simultáneamente, en la misma transacción atómica, insertas el evento en una tabla especial llamada outbox_events.
Change Data Capture: El Motor Que Lo Hace Posible
Un proceso completamente independiente lee continuamente la tabla outbox_events usando Change Data Capture (CDC) y publica los eventos pendientes a Kafka. Una vez que confirma la publicación exitosa, marca los eventos como procesados. La belleza está en las garantías: si la transacción original se confirma exitosamente, el evento SIEMPRE llegará a Kafka eventualmente.
Opciones de Implementación CDC:
- •Debezium: Solución open-source compatible con PostgreSQL, MySQL, MongoDB y SQL Server
- •AWS DMS: Capacidades CDC nativas en servicios gestionados
- •Confluent Connect: Conectores específicos con integración directa a Kafka
Las Garantías que Puedes Confiar
Las garantías que obtienes son fundamentales para sistemas distribuidos confiables:
- •Atomicidad: Si el pedido se guarda, el evento se enviará garantizado
- •Durabilidad: Los eventos se persisten hasta confirmarse su envío exitoso
- •Orden: Los eventos se publican en la secuencia correcta
- •Entrega At-Least-Once: Puede haber duplicados ocasionales por reintentos, pero nunca pérdidas
Saga Pattern: Coordinando Transacciones Distribuidas
En el mundo de los microservicios, las operaciones de negocio complejas a menudo requieren cambios coordinados en múltiples servicios. Las transacciones ACID tradicionales no funcionan a través de servicios distribuidos que pueden estar en diferentes bases de datos, centros de datos, o incluso clouds diferentes. Necesitamos un mecanismo diferente para garantizar consistencia: las Sagas.
Una saga es una secuencia de transacciones locales donde cada transacción actualiza datos dentro de un único servicio. Si una transacción en la secuencia falla, la saga ejecuta una serie de transacciones compensatorias para deshacer los efectos de las transacciones anteriores que ya se completaron.
Loading diagram...
El diagrama muestra un ejemplo típico de saga: reservar un viaje completo que requiere coordinar múltiples servicios. En el flujo exitoso (superior), todos los pasos se completan correctamente. En el flujo con fallo (inferior), cuando la reserva de hotel falla, la saga automáticamente ejecuta la compensación correspondiente: cancelar la reserva de vuelo que ya se había confirmado.
Las sagas pueden implementarse de dos maneras fundamentalmente diferentes, cada una con sus propias ventajas y trade-offs. La primera aproximación es la saga orquestada, donde un componente central actúa como director de orquesta coordinando toda la secuencia y manteniendo el estado de la saga:
Loading diagram...
El orquestador mantiene una máquina de estados sofisticada que define exactamente qué paso ejecutar siguiente y qué compensaciones aplicar cuando algo falla. Esta aproximación ofrece control centralizado y facilita enormemente el debugging (puedes ver el estado completo de la saga en un solo lugar), pero introduce un punto potencial de fallo y cierto grado de acoplamiento entre servicios.
La alternativa es la saga coreografiada, donde no hay director central sino que cada servicio conoce su papel en la danza y reacciona a eventos de manera autónoma:
Loading diagram...
En este modelo descentralizado, cada servicio actúa como un bailarín experto que conoce perfectamente su coreografía: reacciona a eventos específicos y ejecuta su lógica correspondiente sin necesidad de un director. No hay coordinador central, lo que elimina puntos únicos de fallo, pero requiere mucho más cuidado en el diseño para evitar bucles infinitos o estados inconsistentes.
Implementar sagas exitosamente en producción requiere atención meticulosa a varios aspectos críticos. Primero, tus compensaciones deben ser idempotentes: ejecutar "cancelar vuelo" dos veces por un error de red no debe causar problemas adicionales o cobros duplicados. Esta propiedad es fundamental porque en sistemas distribuidos, los fallos de red pueden hacer que los mensajes se entreguen múltiples veces.
El manejo de timeouts también merece cuidado especial. Debes establecer límites de tiempo realistas para cada paso basándote en el comportamiento real de tus servicios. Si el servicio de vuelos normalmente responde en 2 segundos, pero tu timeout está configurado en 30 segundos, estarás creando latencias artificiales. Por el contrario, timeouts demasiado agresivos pueden causar compensaciones innecesarias cuando los servicios están experimentando latencia temporal pero válida.
La semántica de fallos parciales presenta otro desafío interesante: ¿qué haces si una compensación también falla? Necesitas definir claramente tu estrategia: ¿reintentas con backoff exponencial? ¿escalas automáticamente a intervención manual? ¿tienes compensaciones alternativas o de fallback? Cada decisión aquí afecta la confiabilidad global de tu sistema.
La observabilidad se vuelve crítica porque las sagas pueden involucrar decenas de servicios diferentes. Cuando algo falla, necesitas entender exactamente dónde y por qué sin tener que correlacionar manualmente logs de múltiples sistemas. Instrumenta cada paso de la saga con IDs de correlación únicos y métricas específicas que te permitan rastrear el progreso end-to-end.
Finalmente, considera el versionado desde el primer día. Las reglas de negocio evolucionan constantemente, y necesitas garantizar que sagas iniciadas con versiones anteriores puedan completarse correctamente incluso después de desplegar nuevas versiones de servicios. Esto a menudo requiere mantener múltiples versiones de compensaciones o logica de transición elegante entre versiones.
Retos Operacionales en Producción
Garantías de Entrega: Eligiendo el Balance Correcto
Kafka ofrece tres niveles de garantías de entrega, cada uno con trade-offs específicos en términos de rendimiento, latencia, y confiabilidad. Elegir incorrectamente puede ser la diferencia entre un sistema que funciona en desarrollo y uno que falla en producción bajo carga real.
Loading diagram...
El diagrama muestra las tres opciones disponibles y sus características principales. La elección correcta depende completamente de las necesidades específicas de tu aplicación y las consecuencias de cada tipo de fallo.
At-Most-Once: Máximo Rendimiento
La primera opción, at-most-once, es la más sencilla conceptualmente: el productor envía cada mensaje una vez y nunca reintenta. Esto garantiza que nunca tendrás duplicados, pero algunos mensajes pueden perderse durante problemas de red temporales o fallos de brokers.
Casos de Uso Ideales:
- •Sistemas de métricas y telemetría donde perder algunos puntos de datos no afecta las tendencias generales
- •Logs de aplicación no críticos
- •Eventos de tracking de usuario donde la precisión absoluta no es crucial
Configuración: retries=0 para evitar reintentos y acks=0 o acks=1 para no esperar confirmación de todas las réplicas.
At-Least-Once: El Equilibrio Más Común
At-least-once representa el equilibrio más común en aplicaciones empresariales. El productor reintenta envíos hasta recibir confirmación de que el mensaje se almacenó correctamente, garantizando que cada mensaje eventualmente llega a su destino. El trade-off son duplicados ocasionales cuando hay timeouts de red o fallos parciales.
Características:
- •Funciona perfectamente para la mayoría de aplicaciones donde perder datos es inaceptable
- •Requiere que los consumidores implementen lógica idempotente
- •Configuración:
retries>0con backoff exponencial yacks=all
Exactly-Once: Máxima Confiabilidad
La opción más robusta pero también más costosa es exactly-once. Kafka implementa esto usando transacciones distribuidas y producer IDs únicos, garantizando que cada mensaje se entrega y procesa exactamente una vez, eliminando tanto pérdidas como duplicados.
Casos de Uso Críticos:
- •Sistemas financieros donde duplicados pueden causar doble facturación
- •Sistemas de inventario donde duplicados pueden generar sobreventas
- •Aplicaciones de contabilidad donde la precisión absoluta es un requisito legal
Configuración: enable.idempotence=true, un transactional.id único, y uso cuidadoso de transacciones para commits atómicos.
Tu Última Línea de Defensa: Implementando Idempotencia
Más allá de las garantías que elijas a nivel de Kafka, hay un principio fundamental que deberías aplicar siempre: hacer que tu lógica de procesamiento sea idempotente. Esto significa que ejecutar la misma operación múltiples veces produce exactamente el mismo resultado que ejecutarla una vez.
Técnicas de Implementación:
Deduplicación por ID Único: Mantienes un cache (usando Redis o una tabla de base de datos) de IDs de eventos ya procesados. Antes de procesar cualquier evento, verificas si su ID ya existe en el cache.
Operaciones Naturalmente Idempotentes: Favorece operaciones como SET usuario.nombre = "Juan" sobre UPDATE saldo = saldo + 100. La primera es idempotente por naturaleza.
Versionado de Entidades: Cada evento incluye un timestamp o número de versión, y tu lógica de procesamiento solo aplica cambios si la versión del evento es más reciente que la versión actual de la entidad.
Operaciones Upsert: Las operaciones update-or-insert proporcionan idempotencia a nivel de base de datos: insertan un registro si no existe, o lo actualizan si ya existe.
Gestión de Particiones y el Dolor de los Rebalances
Las particiones son la unidad fundamental de paralelismo en Kafka. Cada topic se divide en múltiples particiones, y cada partición puede ser procesada independientemente por diferentes consumidores dentro de un grupo. Pero su gestión incorrecta puede causar problemas serios de rendimiento y disponibilidad.
Loading diagram...
El diagrama muestra cómo Kafka distribuye mensajes usando una función hash sobre la clave del mensaje. Mensajes con la misma clave siempre van a la misma partición, garantizando orden por clave. Cada partición es asignada a exactamente un consumidor del grupo, pero un consumidor puede manejar múltiples particiones. En este ejemplo, el Consumidor A maneja particiones 0 y 1, B maneja 2 y 3, y C maneja 4 y 5.
El Problema del Rebalance: Cuando Todo se Pausa
Cuando consumidores entran o salen del grupo (por despliegues, fallos de aplicación, problemas de red, o scaling horizontal), Kafka debe redistribuir particiones entre los consumidores disponibles. Durante este proceso crítico:
- •Todo el procesamiento se pausa en el grupo completo
- •Puede durar desde segundos hasta minutos según el tamaño del cluster y complejidad de la asignación
- •Causa picos de latencia significativos y acumulación de consumer lag
- •Puede provocar timeouts en aplicaciones que esperan procesamiento en tiempo real
Estrategias para Minimizar el Impacto
Sticky Assignment (Asignación Pegajosa): Esta estrategia minimiza el movimiento de particiones durante rebalances, intentando mantener a cada consumidor con las mismas particiones que tenía antes. Esto preserva el estado local de los consumidores (caches, conexiones de base de datos, etc.) y reduce el tiempo de rebalance significativamente.
Configuración de Timeouts Inteligentes:
- •
session.timeout.ms: tiempo que Kafka espera antes de considerar un consumidor "muerto" - •
heartbeat.interval.ms: frecuencia de heartbeats para mantener la sesión activa - •
max.poll.interval.ms: tiempo máximo entre polls antes de expulsar al consumidor
Coordinación de Despliegues: Implementa despliegues rolling donde los consumidores se detienen gracefully (cerrando conexiones, committeando offsets) antes de recibir SIGKILL. Esto evita rebalances innecesarios por terminaciones abruptas.
Monitoring y Observabilidad: La Clave del Éxito Operacional
En producción, no basta con que el sistema funcione; necesitas saber que funciona y detectar problemas antes de que afecten a usuarios. Los sistemas event-driven introducen complejidad adicional en monitoring porque los fallos pueden propagarse asincrónicamente a través de múltiples servicios.
Métricas Críticas que Debes Monitorear
Nivel de Cluster Kafka:
- •Throughput de mensajes por segundo por topic y partición
- •Consumer lag: cuántos mensajes están pendientes de procesar por grupo
- •Replica synchronization: estado de replicación entre brokers
- •Disk usage y retention: espacio usado vs configuración de retención
Nivel de Aplicación:
- •Latencia end-to-end: tiempo desde que se produce un evento hasta que se procesa completamente
- •Tasa de errores en procesamiento por tipo de evento
- •Dead letter queue size: eventos que fallaron y necesitan investigación
- •Idempotency violations: duplicados detectados y descartados
Herramientas Esenciales para el Monitoreo
- •Kafka Manager/AKHQ: interfaces web para administración visual de clusters
- •Prometheus + Grafana: métricas en tiempo real y alertas proactivas
- •Jaeger/Zipkin: distributed tracing para seguir eventos a través de múltiples servicios
- •ELK Stack: agregación y análisis de logs distribuidos
Schemas y Compatibilidad: Evitando el Caos de Versiones
Cuando múltiples equipos desarrollan servicios que intercambian eventos, mantener compatibilidad entre versiones se vuelve crítico. Un cambio aparentemente inocente en el esquema de un evento puede romper consumidores en producción sin que el productor se entere hasta que es demasiado tarde.
Schema Registry como guardián de la compatibilidad:
Confluent Schema Registry actúa como repositorio centralizado de esquemas con reglas de compatibilidad enforced automáticamente:
Loading diagram...
Tipos de compatibilidad:
Forward Compatibility (Compatibilidad hacia adelante): Consumidores antiguos pueden leer datos producidos con esquemas nuevos. Útil cuando quieres desplegar nuevos productores pero mantener consumidores existentes temporalmente.
Backward Compatibility (Compatibilidad hacia atrás): Consumidores nuevos pueden procesar datos producidos con esquemas antiguos. Esencial cuando actualizas consumidores pero hay eventos antiguos en el topic que aún necesitan procesarse.
Full Compatibility (Compatibilidad completa): Combinación de ambas: tanto productores como consumidores pueden evolucionar independientemente manteniendo compatibilidad bidireccional.
Estrategias prácticas para evolución de esquemas:
Campos opcionales con valores por defecto: Al añadir campos nuevos, hazlos opcionales y define valores por defecto sensatos. Esto permite que consumidores antiguos ignoren campos que no conocen, mientras que consumidores nuevos pueden usar la información adicional.
Versionado semántico de eventos: Incluye información de versión en cada evento para que consumidores puedan manejar múltiples versiones simultáneamente durante períodos de transición.
Deprecación gradual: Antes de eliminar campos, marca como deprecados por al menos un ciclo de release. Implementa warnings en logs cuando detectes uso de campos deprecados.
Casos de Uso Reales y Lecciones Aprendidas
Netflix: Streaming en Tiempo Real a Escala Global
Netflix procesa más de 8 billones de eventos por día usando Kafka para coordinar todo desde recomendaciones personalizadas hasta distribución de contenido global. Su arquitectura event-driven les permite:
Las Capacidades que Transformaron el Streaming
Recomendaciones en Tiempo Real: Cada interacción del usuario (play, pause, skip, rating) genera eventos que alimentan algoritmos de ML para actualizar recomendaciones instantáneamente. Un usuario que para una película de terror a los 5 minutos inmediatamente influye en futuras sugerencias.
Distribución Inteligente de Contenido: Eventos de demanda regional predicen qué contenido pre-posicionar en CDNs locales. Si detectan picos de visualización de una serie en España, automáticamente mueven más copias a servidores europeos antes de que la demanda sature la red.
Lección Clave: Netflix implementó "chaos engineering" para Kafka: deliberadamente causan fallos en producción para garantizar que sus sistemas de eventos sean resilientes. Esto les permitió descubrir y corregir vulnerabilidades antes de que causaran outages reales.
Uber: Coordinando Millones de Viajes Simultáneos
La plataforma de Uber es esencialmente un sistema de eventos masivo donde cada segundo se procesan:
- •Actualizaciones de ubicación de conductores y pasajeros
- •Cambios de estado de viajes (solicitado, asignado, en progreso, completado)
- •Eventos de pricing dinámico basado en demanda y oferta en tiempo real
- •Detección de fraude analizando patrones anómalos instantáneamente
Patrón "Location State Machine": Cada viaje es una saga compleja que coordina múltiples servicios: matching de conductor, cálculo de rutas, procesamiento de pagos, y calificaciones mutuas. Events como "DriverAccepted", "TripStarted", "PaymentProcessed" fluyen a través de Kafka coordinando la experiencia completa.
Lección clave: Uber descubrió que la partición por ciudad era más efectiva que por ID de usuario. Esto permite que eventos relacionados geográficamente se procesen en la misma instancia, optimizando algoritmos de matching y reduciendo latencia de asignación conductor-pasajero.
4.3 LinkedIn: el origen de todo
Como creadores de Kafka, LinkedIn lo usa para alimentar funcionalidades críticas:
Activity streams: Cada acción en la plataforma (like, share, comment, connection) se captura como evento para generar feeds personalizados de millones de usuarios simultáneamente.
People You May Know: Algoritmos de grafos procesan eventos de conexiones en tiempo real para sugerir contactos relevantes basados en redes de segundo y tercer grado.
Lección clave: LinkedIn implementó tiered storage donde eventos recientes se mantienen en SSD rápido, eventos de mediano plazo en HDD tradicional, y eventos históricos en storage de archivado. Esto optimiza costos sin sacrificar performance para casos de uso que requieren acceso a datos históricos.
Antipatrones y Errores Comunes que Debes Evitar
Event as API: Kafka como API REST Disfrazada
Uno de los errores más comunes que veo en equipos que adoptan event-driven architecture es tratar Kafka como si fuera una API REST con mejor marketing. El patrón típico es enviar un evento como "ObtenerUsuario" y después sentarse a esperar una respuesta en otro topic, implementando timeouts y manejo de errores como si fuera una llamada HTTP síncrona.
Este enfoque malinterpreta fundamentalmente para qué está optimizado Kafka. La plataforma brilla en throughput alto y tolerancia a fallos, no en latencia baja para request-response. Al usar eventos síncronamente, eliminas las ventajas principales del desacoplamiento temporal que justifican la complejidad de adoptar Kafka en primer lugar.
Solución: Usa HTTP/gRPC para consultas síncronas que necesitan respuesta inmediata, y reserva eventos exclusivamente para notificaciones asíncronas donde el tiempo de respuesta no es crítico. Si te encuentras esperando respuestas de eventos, probablemente necesitas una API tradicional.
La Tentación de la Base de Datos Compartida
Otro antipatrón insidioso surge cuando múltiples servicios empiezan leyendo directamente de la misma base de datos que actúa como "event store" compartido. Al principio parece conveniente: todos los eventos están en un lugar, las consultas son familiares, y no necesitas configurar Kafka para casos simples.
Pero esto reintroduce exactamente el acoplamiento que intentas evitar con microservicios. Creas cuellos de botella en la base de datos compartida, eliminas la posibilidad de escalar servicios independientemente, y acabas con el peor de ambos mundos: la complejidad de múltiples servicios pero sin las ventajas de aislamiento.
Solución: Cada servicio debe tener su propia base de datos privada y comunicarse únicamente a través de eventos. Si necesitas datos de otro servicio, suscríbete a sus eventos y mantén una proyección local. Puede parecer duplicación, pero es la duplicación que te permite evolucionar independientemente.
Granularidad Excesiva: Cuando Cada Campo es un Evento
Un error que veo frecuentemente es generar eventos separados para cada cambio microscópico: NombreUsuarioCambiado, EmailUsuarioActualizado, TelefonoUsuarioModificado. La lógica parece sólida: máxima granularidad significa máxima flexibilidad para los consumidores.
En realidad, esto produce una explosión de eventos que son pesadillas para correlacionar. Los consumidores que necesitan una vista completa del usuario tienen que suscribirse a docenas de tipos de eventos diferentes. Peor aún, si eventos relacionados llegan desordenados (lo cual puede pasar en sistemas distribuidos), puedes acabar con estados temporalmente inconsistentes.
Solución: La granularidad correcta agrupa cambios relacionados en eventos cohesivos como PerfilUsuarioActualizado que incluye todos los campos modificados junto con sus valores anteriores y nuevos. Esto proporciona contexto completo a los consumidores sin fragmentar excesivamente el flujo de información.
El Versionado que Nunca Llega
Quizás el antipatrón más costoso a largo plazo es desplegar eventos sin esquemas formales ni estrategia de versionado, asumiendo optimistamente que "nunca cambiarán". Esta mentalidad es comprensible: en las etapas tempranas de un proyecto, los esquemas parecen estables y el overhead de versionado parece innecesario.
Pero los requisitos de negocio evolucionan de manera inevitable y a menudo impredecible. Sin versionado planificado, cada cambio se convierte en una migración coordinada y dolorosa que requiere sincronizar despliegues de múltiples equipos simultáneamente. He visto este antipatrón paralizar organizaciones enteras durante semanas.
Solución: La inversión en Schema Registry y versionado semántico desde día uno es seguro más barato que cualquier migración futura. Planifica para evolución backward-compatible por defecto, y trata el schema de tus eventos con el mismo rigor que las APIs públicas, porque esencialmente eso es lo que son.
Conclusiones y Perspectivas Futuras
Las arquitecturas event-driven con Apache Kafka han dejado de ser una tendencia experimental para convertirse en la columna vertebral de los sistemas distribuidos modernos. Empresas que procesan billones de eventos diarios han demostrado que estos patrones no solo escalan técnicamente, sino que también permiten velocidad de desarrollo y flexibilidad de negocio que sería imposible con arquitecturas tradicionales.
Lo que Hemos Aprendido
Event Sourcing nos enseña que el proceso de llegada a un estado es tan valioso como el estado mismo. En un mundo donde la auditabilidad, compliance, y capacidad de análisis histórico son críticos, almacenar la historia completa no es un lujo sino una necesidad.
CQRS reconoce que optimizar para lecturas y escrituras simultáneamente es un compromiso que limita ambas. Separar estas responsabilidades permite que cada lado use las tecnologías y optimizaciones más apropiadas para su propósito específico.
Outbox Pattern y Saga Pattern resuelven los problemas más sutiles pero peligrosos de consistencia en sistemas distribuidos. No son complicaciones académicas sino soluciones prácticas a problemas reales que aparecen cuando sistemas simples crecen hasta volverse críticos para el negocio.
Los Retos Siguen Siendo Reales
Adoptar estas arquitecturas requiere inversión significativa en herramientas de monitoring, expertise en sistemas distribuidos, y disciplina operacional que va más allá de simplemente escribir código. Los rebalances de Kafka, la gestión de schemas, y el debugging de flujos asincrónicos presentan desafíos únicos que no existen en sistemas monolíticos.
Estos costos se amortizan cuando tu sistema necesita escalar más allá de un equipo, una base de datos, o un centro de datos. La pregunta no es si necesitarás estas arquitecturas, sino cuándo.
Hacia Dónde Vamos
El ecosistema continúa evolucionando rápidamente:
Kafka Streams y ksqlDB están democratizando el stream processing, permitiendo que equipos sin expertise profunda en sistemas distribuidos implementen procesamiento de eventos sofisticado.
Service mesh y observability tools están madurando para proporcionar visibilidad end-to-end que hace estos sistemas más debuggeables y operables.
Serverless event processing con funciones cloud está reduciendo la complejidad operacional, aunque con trade-offs en control y costos en escala.
Tu Próximo Paso
Si estás comenzando tu journey hacia arquitecturas event-driven:
- •Empieza pequeño pero piensa grande: implementa un flujo simple de eventos entre dos servicios, pero diseña tu infraestructura para escalar
- •Invierte en observabilidad desde día uno: la complejidad de debugging aumenta exponencialmente con cada servicio añadido
- •Aprende de los errores de otros: los antipatrones descritos son reales y costosos; evítalos desde el principio
- •Abraza la asincronía: deja de pensar síncronamente y diseña para eventual consistency
¿Te ha resultado útil esta guía? Si necesitas ayuda para implementar estos patrones en tu proyecto, no dudes en ponerte en contacto con Caricalia